
Six Degrees of Hollywood
This project started from humble beginnings as part of a homework assignment for my first algorithms course, CS50-AI from Harvard University offered by EdX. The assignment was to write a path-finding algorithm (Breadth-First Search) to navigate through a few dozen data points. As I worked on the assignment, I started wondering if I could expand this idea by using a larger dataset.
If you are unfamiliar with the concept, the idea behind the project name, is that any two actors can be connected through their roles in movies within six steps or fewer. This notion is rooted in the broader “Six Degrees of Separation” theory, which suggests that everyone in the world is six or fewer social connections away from each other.
I eventually found a substantial dataset from IMDb, consisting of multiple relational tables, and decided to take on the challenge of working with it. Extracting the relevant data in the correct format proved to be challenging. The project’s GitHub repository (linked here) provides a more comprehensive write-up of these challenges.
The first module of this program downloads the dataset, performs extraction, transformation, and loading (ETL) into PostgreSQL. The second module uses that database to prompt the user for names and attempts to find the closest probable match. Finally, given keys to the TMDB API, the program generates an image with headshots and movie posters.
The program in Images
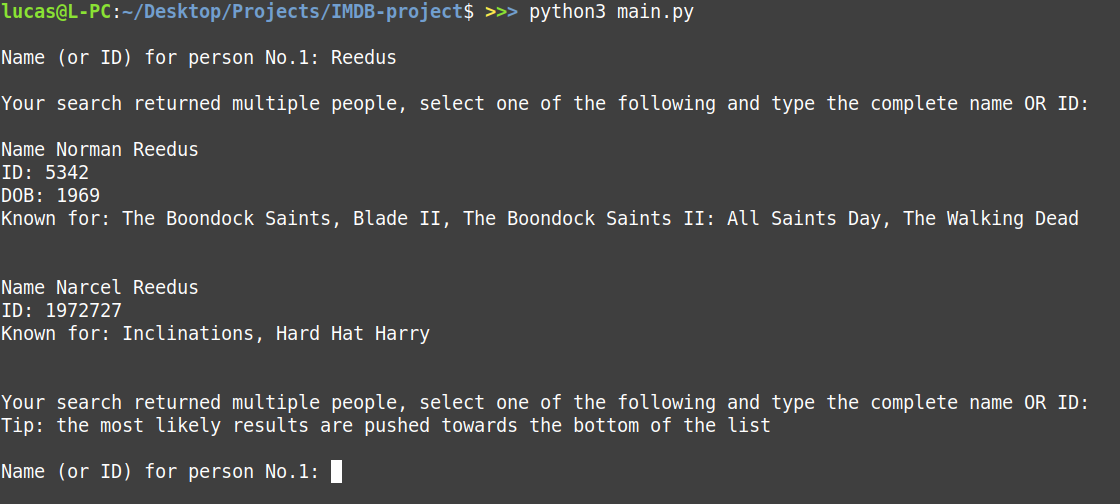
If the program find multiple names that match the searched name, it ranks results based on relevance
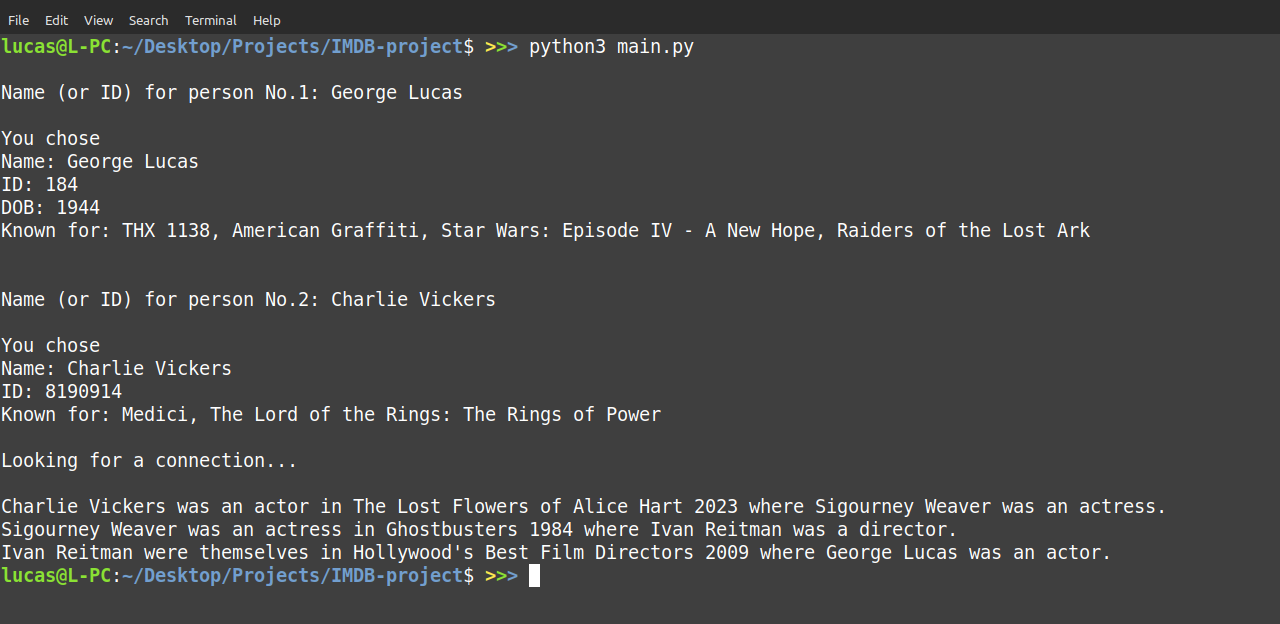
The found connection between the two selected persons.

After finding the connection, the program fetches images to create a simple picture of the result! Sometimes a headshot or poster image is not found and style could certainly be eventually improved.
Learning Points
-
Extract, Transform, and Load (ETL): This project introduced me to the ETL process, which is essential for working with large datasets. I learned how to extract raw data, transform it into a usable format, and load it into a database efficiently.
-
APIs: I gained experience working with APIs, specifically the TMDB API, to retrieve movie data and images. This taught me how to integrate third-party services into my projects and handle API responses.
-
PostgreSQL: Managing a relational database was a critical part of this project. I learned how to design schemas, write complex queries, and optimize performance for large datasets using PostgreSQL.
-
Image Creation with Pillow: The project required generating images that combined headshots and movie posters. I used the Pillow library in Python to create and manipulate images programmatically, which added a visual element to the project.
-
Modularity: As the project grew in complexity, I realized the importance of modularity in code design. I learned to break down the project into separate, manageable modules that could be developed, tested, and maintained independently.